Show the code
---
title: Ask Fedora
description: Trends on Ask Fedora data from Fedora Discussion.
date: 2025-10-12
---{'title': 'Ask Fedora', 'refresh': 'monthly'}---
title: Ask Fedora
description: Trends on Ask Fedora data from Fedora Discussion.
date: 2025-10-12
---{'title': 'Ask Fedora', 'refresh': 'monthly'}# common fedora commops analytics includes
import pyarrow.dataset as ds
import pyarrow.parquet as pq
import pandas as pd
import pyarrow as pa
import matplotlib.pyplot as plt
import seaborn as sns
import json
from datetime import datetime
from collections import defaultdict
import os
from pyarrow import fs
import pyarrow.dataset as ds
from pathlib import Path# @replace DATA_SOURCES
DATA_SOURCES = {"datagrepper-topics": "/home/jovyan/work/bus2parquet/output_parquets"}
parquet_dir = DATA_SOURCES["datagrepper-topics"]
topic = "org.fedoraproject.prod.discourse.topic.topic_created"
cutoff_date = (pd.Timestamp.now().replace(day=1) - pd.DateOffset(months=12)).date()
files = []
for p in Path(f"{parquet_dir}/{topic}").glob("fedora-*.parquet"):
stem = p.stem.replace(f"-{topic}", "")
d = datetime.strptime(stem.split("-")[1], "%Y%m%d").date()
# if d >= cutoff_date and os.path.getsize(p) > 0:
if os.path.getsize(p) > 0:
files.append(str(p))
local_fs = fs.LocalFileSystem()
tables = []
# First pass: collect all schemas
all_fields = {}
for f in files:
try:
tbl = pq.read_table(f)
for name in tbl.schema.names:
all_fields[name] = pa.string() # force everything to string
except Exception as e:
print(f"[WARN] Skipping {f}: {e}")
# Build unified schema
unified_schema = pa.schema([pa.field(name, pa.string()) for name in sorted(all_fields)])
# Second pass: cast each table to unified schema
for f in files:
try:
tbl = pq.read_table(f)
# Cast existing columns to string
casted = {}
for name in tbl.schema.names:
col = tbl[name].cast(pa.string())
casted[name] = col
# Add missing columns as null strings
for name in unified_schema.names:
if name not in casted:
casted[name] = pa.array([None] * len(tbl), type=pa.string())
# Build new table with unified schema
new_tbl = pa.table([casted[name] for name in unified_schema.names], schema=unified_schema)
tables.append(new_tbl)
except Exception as e:
print(f"[WARN] Skipping {f}: {e}")
if tables:
table = pa.concat_tables(tables, promote=True)
df = table.to_pandas()
print(f"Loaded {len(df)} records from {len(tables)} tables.")
else:
print("No valid parquet files found")/opt/conda/lib/python3.11/site-packages/IPython/core/interactiveshell.py:3526: FutureWarning: promote has been superseded by promote_options='default'.
exec(code_obj, self.user_global_ns, self.user_ns)Loaded 1465 records from 1149 tables.ask = df[df["webhook_body_topic_category_id"] == '6'].copy()
ask["created_at"] = pd.to_datetime(ask["webhook_body_topic_created_at"], errors="coerce")topics_per_month = (
ask.groupby(ask["created_at"].dt.to_period("M"))
.size()
.rename("count")
)
topics_per_month.index = topics_per_month.index.to_timestamp()
plt.figure(figsize=(12,5))
topics_per_month.plot(kind="line", marker="o", color="teal")
plt.title("Ask Fedora: New Topics per Month")
plt.ylabel("Topics created")
plt.xlabel("Month")
plt.grid(True)
plt.show()/tmp/ipykernel_941902/3006604667.py:2: UserWarning: Converting to PeriodArray/Index representation will drop timezone information.
ask.groupby(ask["created_at"].dt.to_period("M"))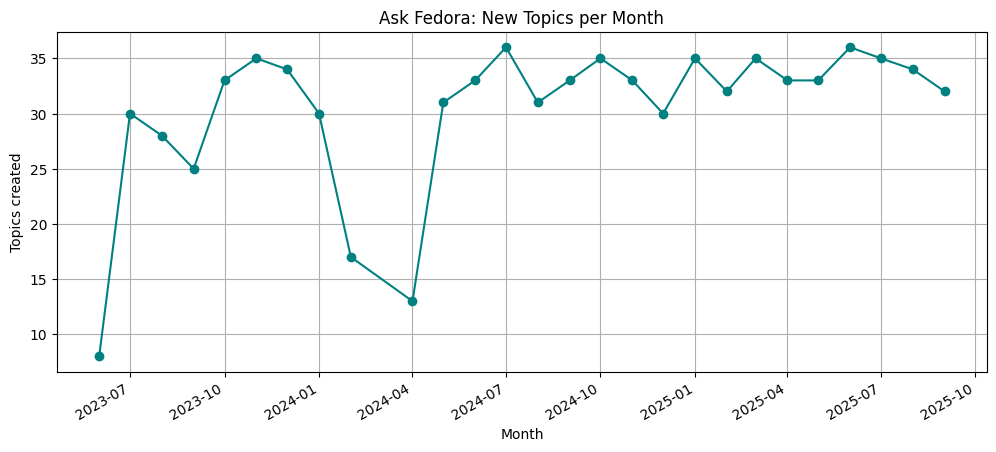
tag_cols = [c for c in ask.columns if c.startswith("webhook_body_topic_tags_")]
tags = pd.Series(
ask[tag_cols].values.ravel("K")
).dropna()
tags = tags[tags != "None"]
top_tags = tags.value_counts().head(15)
plt.figure(figsize=(10,5))
top_tags.plot(kind="bar", color="green")
plt.title("Top 15 Tags in Ask Fedora Topics")
plt.ylabel("Count")
plt.show()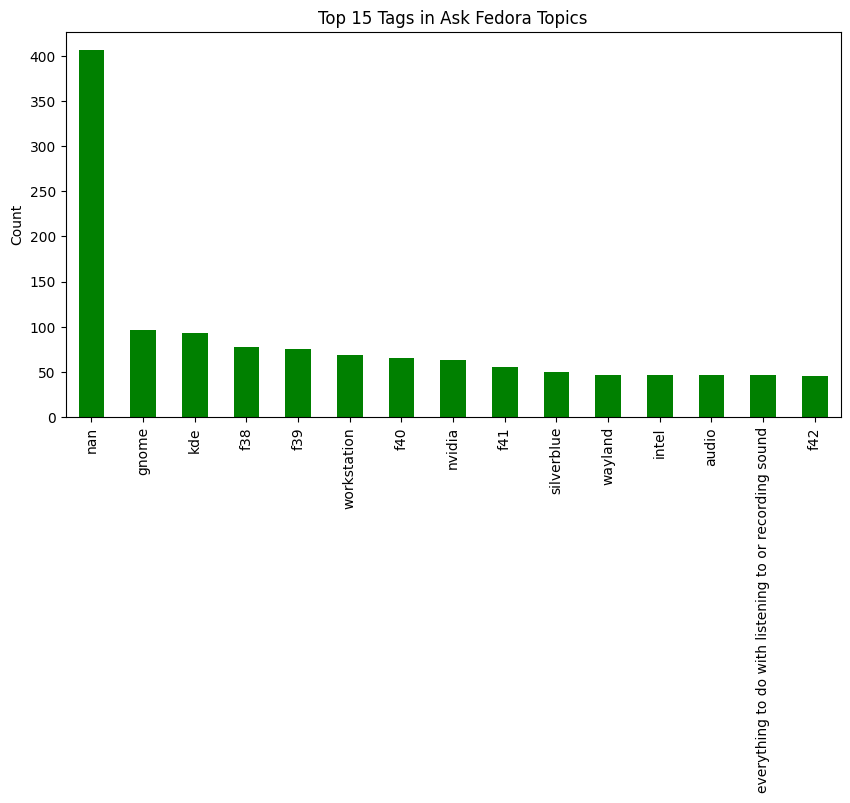
plt.figure(figsize=(8,5))
ask["webhook_body_topic_word_count"].astype(float).hist(bins=40, color="steelblue")
plt.title("Distribution of Word Counts in Ask Fedora Topics")
plt.xlabel("Word count")
plt.ylabel("Topic count")
plt.show()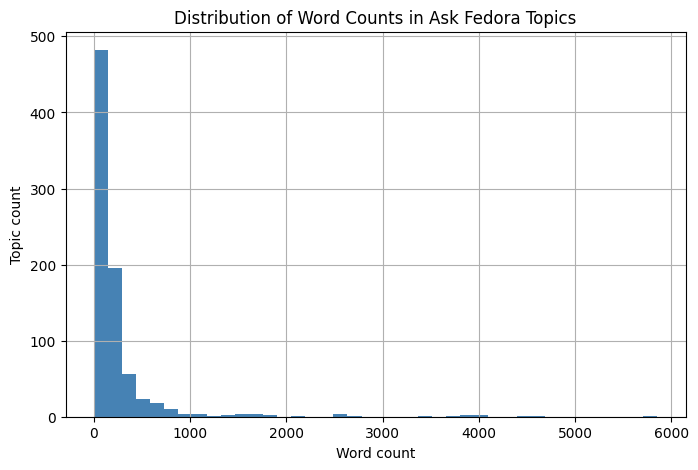
top_creators = (
ask["webhook_body_topic_created_by_username"]
.value_counts()
.head(15)
)
plt.figure(figsize=(10,5))
top_creators.plot(kind="bar", color="coral")
plt.title("Top 15 Topic Creators in Ask Fedora")
plt.ylabel("Number of topics created")
plt.show()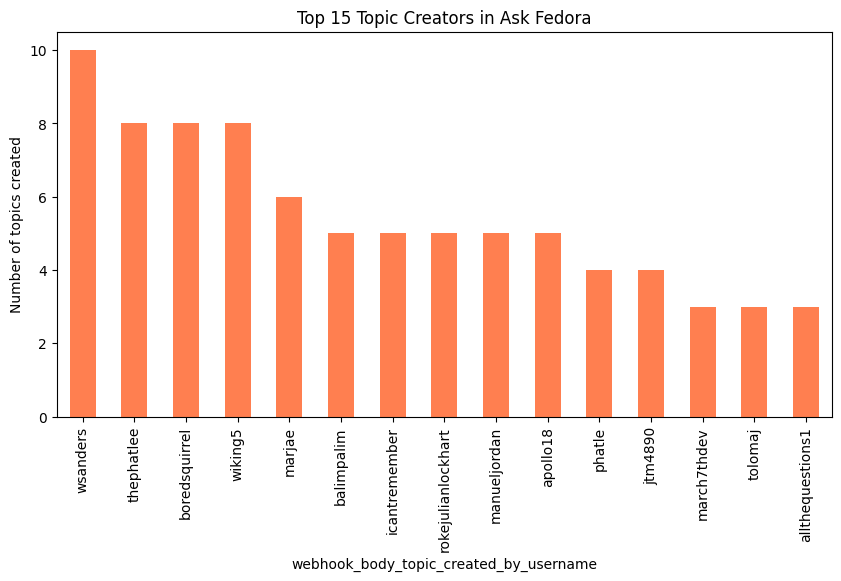
# Cross-year comparison
ask["year"] = ask["created_at"].dt.year
topics_per_year = ask.groupby("year").size()
plt.figure(figsize=(8,5))
topics_per_year.plot(kind="bar", color="teal")
plt.title("Ask Fedora: Topics Created per Year")
plt.ylabel("Number of topics")
plt.xlabel("Year")
plt.xticks(rotation=0)
plt.show()
print("Topics per year:\n", topics_per_year)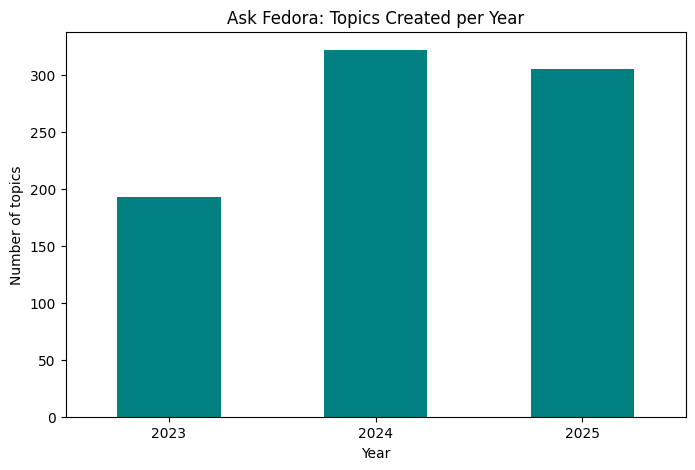
Topics per year:
year
2023 193
2024 322
2025 305
dtype: int64