Show the code
---
title: Mailman Posts vs Discourse Posts by Month
description: Trend of Mailmain vs Discourse posts/topics by month.
date: 2025-10-12
---{'title': 'Mailman Posts vs Discourse Posts by Month', 'refresh': 'weekly'}---
title: Mailman Posts vs Discourse Posts by Month
description: Trend of Mailmain vs Discourse posts/topics by month.
date: 2025-10-12
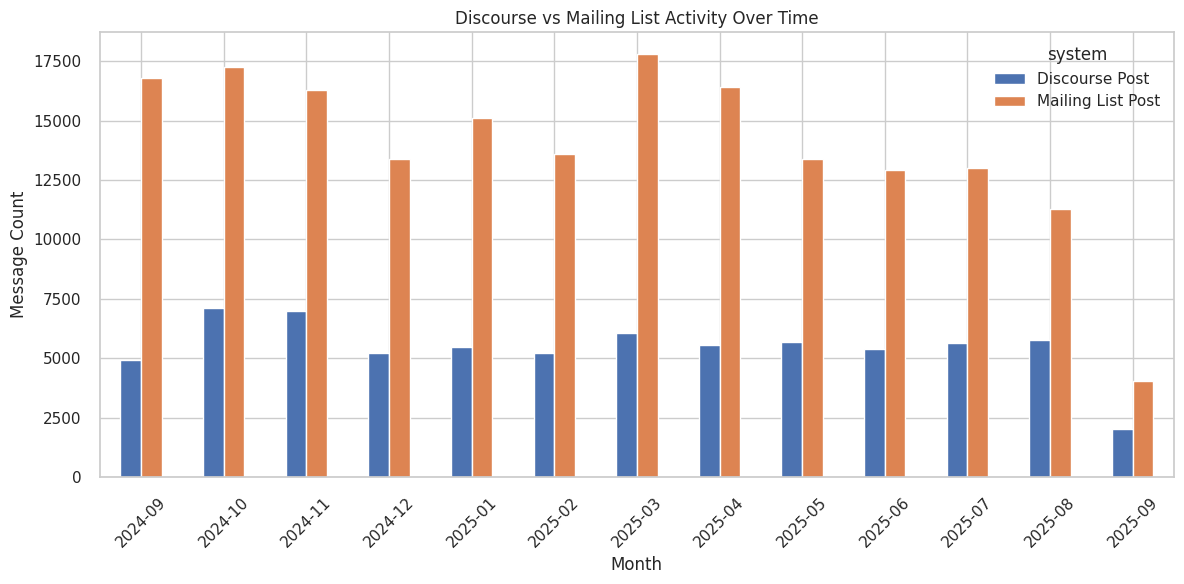
---{'title': 'Mailman Posts vs Discourse Posts by Month', 'refresh': 'weekly'}Trend of Mailmain vs Discourse posts/topics by month. For mailmain, we assume all message is a post. For Discourse, we treat both the Topic creation event and the Post creation event as a post. This does not double count as a topic is the first message and a post is the message after the topic.
We are not including additional items such as: * Discourse Likes / Emoji Flagging on Posts * Discourse Post / Topic Edits
import os
import glob
from pathlib import Path
from datetime import datetime, timedelta
from collections import defaultdict
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import pyarrow as pa
import pyarrow.dataset as ds
import pyarrow.parquet as pq
plt.style.use("seaborn-v0_8")
sns.set_theme(context="notebook", style="whitegrid")# @replace DATA_SOURCES
DATA_SOURCES = {"datagrepper-parse-accounts": "/home/jovyan/work/bus2parquet/output_users"}
parquet_dir = DATA_SOURCES["datagrepper-parse-accounts"]
cutoff_date = (pd.Timestamp.now().replace(day=1) - pd.DateOffset(weeks=52)).date()
files = []
for p in Path(parquet_dir).glob("fedora-*.parquet"):
stem = p.stem.replace("_processed", "")
d = datetime.strptime(stem.split("-")[1], "%Y%m%d").date()
if d >= cutoff_date:
files.append(str(p))
dataset = ds.dataset(files, format="parquet")
chunks = []
for batch in dataset.to_batches(batch_size=50_000):
df = batch.to_pandas()
if "sent_at" not in df.columns or "username" not in df.columns:
continue
df["sent_at"] = pd.to_datetime(df["sent_at"], errors="coerce").dt.floor("s")
chunks.append(df)
combined_df = pd.concat(chunks, ignore_index=True) if chunks else pd.DataFrame()
if not combined_df.empty:
print("Maximum date in data:", combined_df["sent_at"].max().date())
print("Minimum date in data:", combined_df["sent_at"].min().date())
else:
print("No data found in cutoff range")Maximum date in data: 2025-09-10
Minimum date in data: 2024-09-02combined_df['month'] = combined_df['sent_at'].dt.to_period('M')
def classify_system(topic):
if topic.startswith('org.fedoraproject.prod.discourse.topic.topic_created') or \
topic.startswith('org.fedoraproject.prod.discourse.post.post_created'):
return 'Discourse Post'
elif topic == 'org.fedoraproject.prod.mailman.receive':
return 'Mailing List Post'
else:
return 'Other'
combined_df['system'] = combined_df['topic'].map(classify_system)
filtered_df = combined_df[combined_df['system'].isin(['Discourse Post', 'Mailing List Post'])]
activity_summary = (
filtered_df
.groupby(['month', 'system'])
.size()
.unstack(fill_value=0)
.sort_index()
)activity_summary.plot(kind='bar', figsize=(12,6))
plt.title('Discourse vs Mailing List Activity Over Time')
plt.xlabel('Month')
plt.ylabel('Message Count')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()