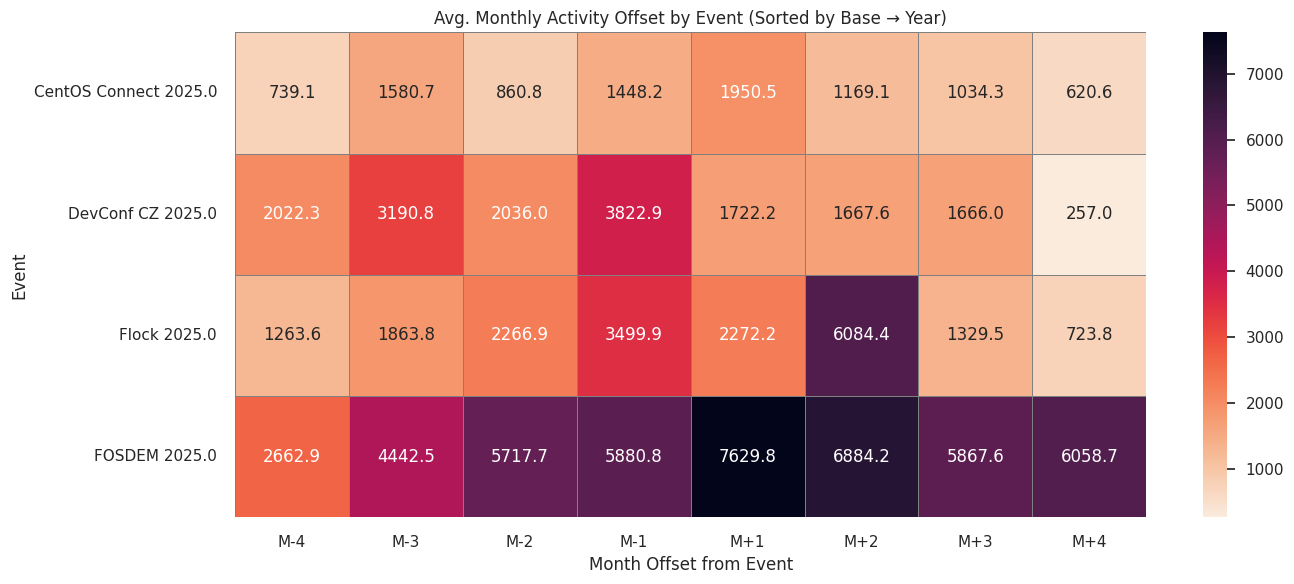
Review of attendees of events, their return rates, and how events impact contribution.
Author
Robert Wright (rwright@)
Published
November 16, 2025
Show the code
import osimport globfrom pathlib import Pathfrom datetime import datetime, timedeltafrom collections import defaultdictimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsimport pyarrow as paimport pyarrow.dataset as dsimport pyarrow.parquet as pqplt.style.use("seaborn-v0_8")sns.set_theme(context="notebook", style="whitegrid")
Show the code
# @replace DATA_SOURCESDATA_SOURCES = {"badges": "/home/jovyan/work/badge/output", "datagrepper-parse-accounts": "/home/jovyan/work/bus2parquet/output_users"}parquet_dir = DATA_SOURCES["datagrepper-parse-accounts"]badge_data = DATA_SOURCES["badges"] +"/badge.csv"cutoff_date = (pd.Timestamp.now().replace(day=1) - pd.DateOffset(weeks=52)).date()files = []for p in Path(parquet_dir).glob("fedora-*.parquet"): stem = p.stem.replace("_processed", "") d = datetime.strptime(stem.split("-")[1], "%Y%m%d").date()if d >= cutoff_date: files.append(str(p))dataset = ds.dataset(files, format="parquet")chunks = []for batch in dataset.to_batches(batch_size=50_000): df = batch.to_pandas()if"sent_at"notin df.columns or"username"notin df.columns:continue df["sent_at"] = pd.to_datetime(df["sent_at"], errors="coerce").dt.floor("s") chunks.append(df)combined_df = pd.concat(chunks, ignore_index=True) if chunks else pd.DataFrame()ifnot combined_df.empty:print("Maximum date in data:", combined_df["sent_at"].max().date())print("Minimum date in data:", combined_df["sent_at"].min().date())else:print("No data found in cutoff range")activity = combined_df# Get account creation timesfas_df = activity[activity["topic"] =="org.fedoraproject.prod.fas.user.create"]account_ages = fas_df.groupby("username")["sent_at"].min().reset_index()account_ages.columns = ["username", "account_created"]# Load badge CSVbadge_df = pd.read_csv(badge_data, parse_dates=["timestamp"])print("Latest Badges data timestamp:", badge_df["timestamp"].max())badge_df.rename(columns={"fas": "username"}, inplace=True)print("Latest Event Badges data timestamp:", badge_df["timestamp"].max())
Maximum date in data: 2025-11-15
Minimum date in data: 2024-11-02
Latest Badges data timestamp: 2025-11-16 00:30:42.328752
Latest Event Badges data timestamp: 2025-11-16 00:30:42.328752
Show the code
import redef parse_badge_id(badge_id: str):""" Parse a badge_id like 'flock-2024-attendee' into components. Returns: (base, year, role) """ m = re.match(r"([a-z0-9.\-]+)-(\d{4})-([a-z]+)", badge_id)if m: base, year, role = m.groups()return base, int(year), rolereturnNone, None, Nonebadge_df[["event_base", "event_year", "event_role"]] = badge_df["badge_id"].apply(lambda b: pd.Series(parse_badge_id(b)))event_display_map = {"flock": "Flock","fosdem": "FOSDEM","devconf.cz": "DevConf CZ","devconf.us": "DevConf US","devconf.in": "DevConf India","centos-connect": "CentOS Connect","fedora-mentor-summit": "Mentor Summit","redhat-summit": "Red Hat Summit",}badge_df["event_display"] = ( badge_df["event_base"].map(event_display_map).fillna(badge_df["event_base"].str.title())+" "+ badge_df["event_year"].astype(str))event_successors = {}for base, g in badge_df.groupby("event_base"): years =sorted(g["event_year"].dropna().unique())for y1, y2 inzip(years[:-1], years[1:]): src =f"{event_display_map.get(base, base.title())}{y1}" dst =f"{event_display_map.get(base, base.title())}{y2}" event_successors[src] = dst
Show the code
# Per-event profile (fixed to use event_display)records = []for event, group in badge_df.groupby("event_display"): usernames = group["username"].unique() event_time = pd.to_datetime(group["timestamp"].min()) subset = activity[activity["username"].isin(usernames)].copy() subset["month_offset"] = ((subset["sent_at"] - event_time) / pd.Timedelta(days=30)).round().astype(int) subset["bucket"] = subset["month_offset"].apply(lambda x: f"M{x:+d}"if-4<= x <=4elseNone ) subset.loc[subset["bucket"] =="M+0", "bucket"] ="M0" msg_counts = subset[subset["bucket"].notnull()].groupby(["username", "bucket"]).size().unstack(fill_value=0) users = pd.DataFrame({"username": usernames}) badge_times = group.groupby("username")["timestamp"].min() users["badge_awarded_at"] = users["username"].map(badge_times) users["account_created"] = users["username"].map(account_ages.set_index("username")["account_created"]) users["days_before_event"] = (event_time - users["account_created"]).dt.days users["newcomer_30d"] = users["days_before_event"] <=30for row in users.itertuples(): profile = {"event_display": event, # <-- updated"event_base": group["event_base"].iloc[0], # useful for grouping later"event_year": group["event_year"].iloc[0], # keep numeric year"event_date": event_time.date(),"username": row.username,"badge_awarded_at": row.badge_awarded_at,"newcomer_30d": row.newcomer_30d }for m in [f"M{-i}"for i inrange(4, 0, -1)] + [f"M+{i}"for i inrange(1, 5)]: profile[m] = msg_counts.loc[row.username, m] if row.username in msg_counts.index and m in msg_counts.columns else0 records.append(profile)df = pd.DataFrame(records)assert"username"in df.columns# Flag return using dynamic successorsif event_successors:for src, succ in event_successors.items(): future_users =set(badge_df[badge_df["event_display"] == succ]["username"]) df.loc[df["event_display"] == src, "returned_next_year"] = df["username"].isin(future_users)
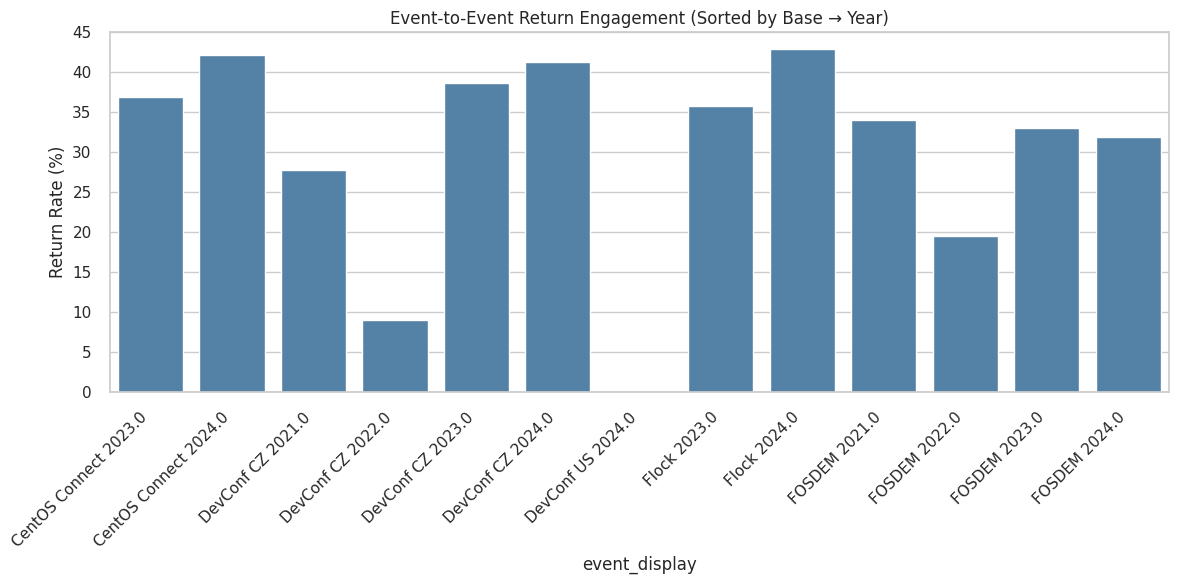
Newcomer Composition by Event
Number of newcomers (joined ≤30 days before event) per event.
Show the code
# Apply event_display_map, drop events that aren't in the mapbadge_df["event_display"] = badge_df["event_base"].map(event_display_map) +" "+ badge_df["event_year"].astype(str)# Remove rows where event_display_map didn't have a mappingbadge_df = badge_df[badge_df["event_base"].isin(event_display_map.keys())].copy()# Add helper columndf["contributor_type"] = df["newcomer_30d"].map({True: "Newcomer", False: "Existing"})