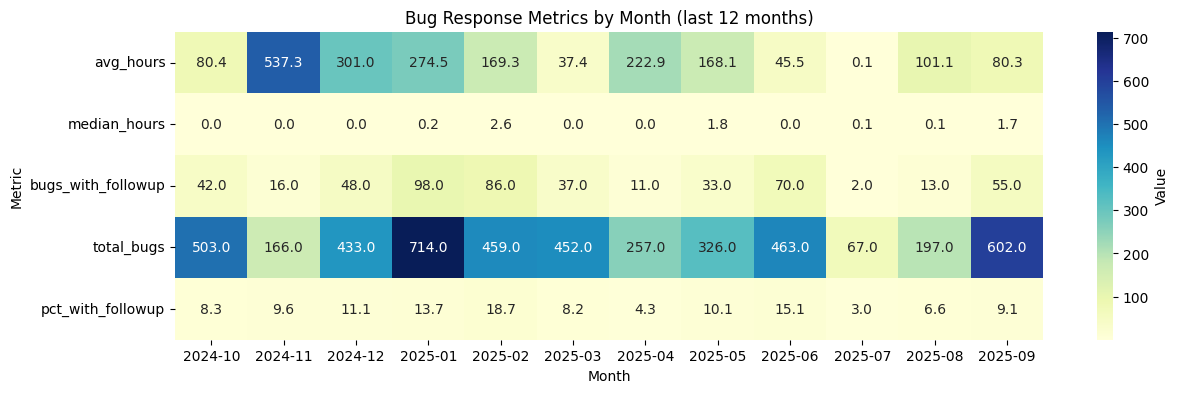
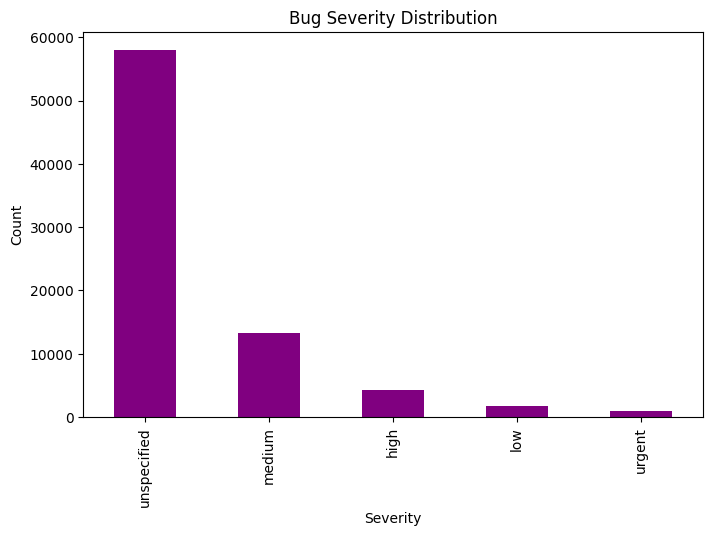
# Convert creation time to datetime
df["bug_creation_time"] = pd.to_datetime(df["bug_creation_time"].astype(float), unit="s", errors="coerce")
# Restrict to the last 12 months
cutoff = pd.Timestamp.now() - pd.DateOffset(months=12)
recent = df[df["bug_creation_time"] >= cutoff].copy()
# Create a year-month column
recent["month"] = recent["bug_creation_time"].dt.to_period("M").astype(str)
# Count unique bug_ids by component per month
monthly_counts = (
recent.groupby(["month", "bug_component"])["bug_id"]
.nunique()
.reset_index(name="bug_count")
)
# Rank components by bug count each month
monthly_counts["rank"] = monthly_counts.groupby("month")["bug_count"].rank(method="first", ascending=False)
# Pivot for a heatmap-style view (optional)
pivot = monthly_counts.pivot(index="month", columns="bug_component", values="bug_count").fillna(0)
print("Top 10 components overall in last 12 months:")
print(monthly_counts.groupby("bug_component")["bug_count"].sum().sort_values(ascending=False).head(10))
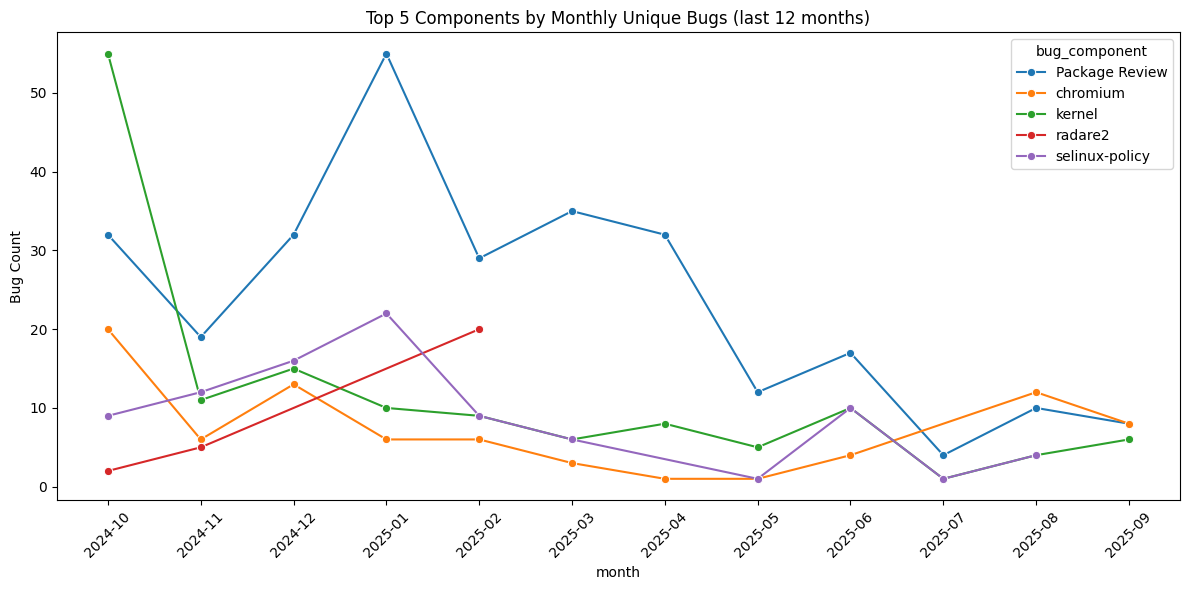
# Example plot: top 5 components trend
top5 = monthly_counts.groupby("bug_component")["bug_count"].sum().nlargest(5).index
plot_df = monthly_counts[monthly_counts["bug_component"].isin(top5)]
plt.figure(figsize=(12,6))
sns.lineplot(data=plot_df, x="month", y="bug_count", hue="bug_component", marker="o")
plt.title("Top 5 Components by Monthly Unique Bugs (last 12 months)")
plt.ylabel("Bug Count")
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()