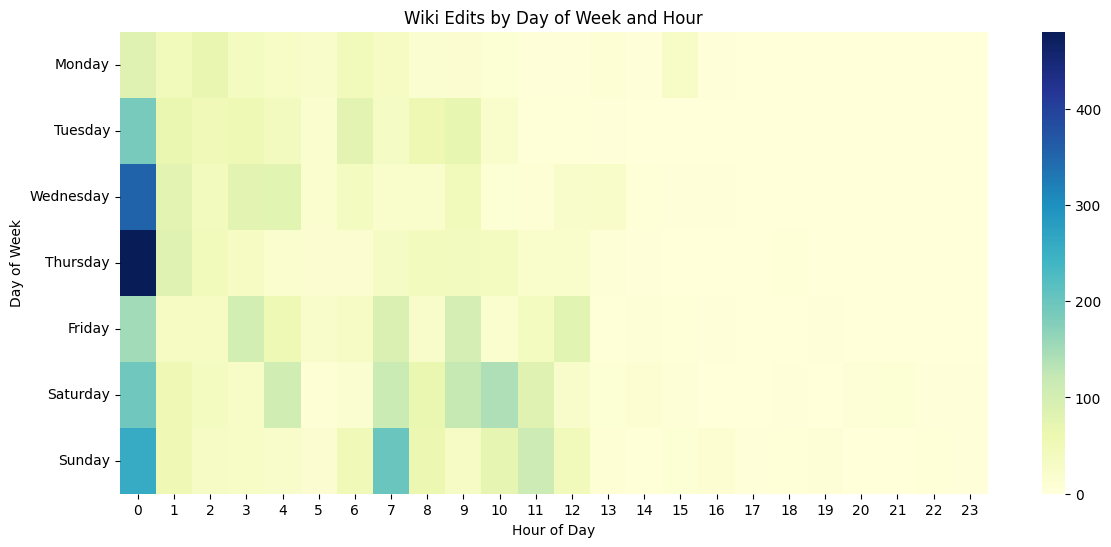
# Drop invalid timestamps
wiki = wiki.dropna(subset=["sent_at"]).copy()
wiki["day_of_week"] = wiki["sent_at"].dt.day_name()
wiki["hour"] = wiki["sent_at"].dt.hour
heatmap_data = wiki.groupby(["day_of_week", "hour"]).size().unstack(fill_value=0)
# Order weekdays
days_order = ["Monday","Tuesday","Wednesday","Thursday","Friday","Saturday","Sunday"]
heatmap_data = heatmap_data.reindex(days_order)
plt.figure(figsize=(14,6))
sns.heatmap(heatmap_data, cmap="YlGnBu")
plt.title("Wiki Edits by Day of Week and Hour")
plt.xlabel("Hour of Day")
plt.ylabel("Day of Week")
plt.show()